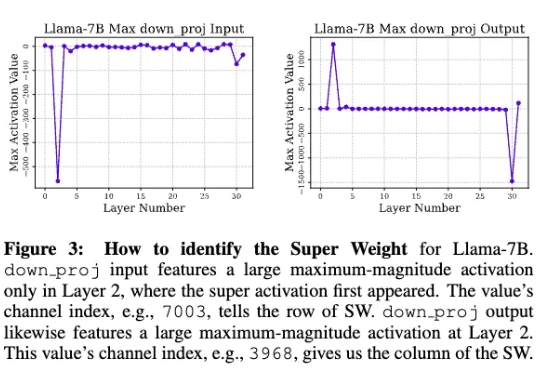
0.01%参数定生死!苹果揭秘LLM「超级权重」,删掉就会胡说八道
0.01%参数定生死!苹果揭秘LLM「超级权重」,删掉就会胡说八道苹果研究人员发现,在大模型中,极少量的参数,即便只有0.01%,仍可能包含数十万权重,他们将这一发现称为「超级权重」。超级权重点透了大模型「命门」,使大模型走出「炼丹玄学」。
来自主题: AI技术研报
8648 点击 2025-09-06 11:27
 搜索
搜索
苹果研究人员发现,在大模型中,极少量的参数,即便只有0.01%,仍可能包含数十万权重,他们将这一发现称为「超级权重」。超级权重点透了大模型「命门」,使大模型走出「炼丹玄学」。
近年来,扩散大语言模型(Diffusion Large Language Models, dLLMs)正迅速崭露头角,成为文本生成领域的一股新势力。与传统自回归(Autoregressive, AR)模型从左到右逐字生成不同,dLLM 依托迭代去噪的生成机制,不仅能够一次性生成多个 token,还能在对话、推理、创作等任务中展现出独特的优势。
大语言模型(Large Language Model, LLM)在复杂推理任务中表现卓越。借助链式思维(Chain-of-Thought, CoT),LLM 能够将复杂问题分解为简单步骤,充分探索解题思路并得出正确答案。LLM 已在多个基准上展现出优异的推理能力,尤其是数学推理和代码生成。
大语言模型(Large Language Models,LLMs)技术的迅猛发展,正在深刻重塑医疗行业。医疗领域正成为这一前沿技术的 “新战场” 之一。大模型具备强大的文本理解与生成能力,能够快速读取医学文献、解读病历记录,甚至基于患者表述生成初步诊断建议,有效辅助医生提升诊断的准确性与效率。
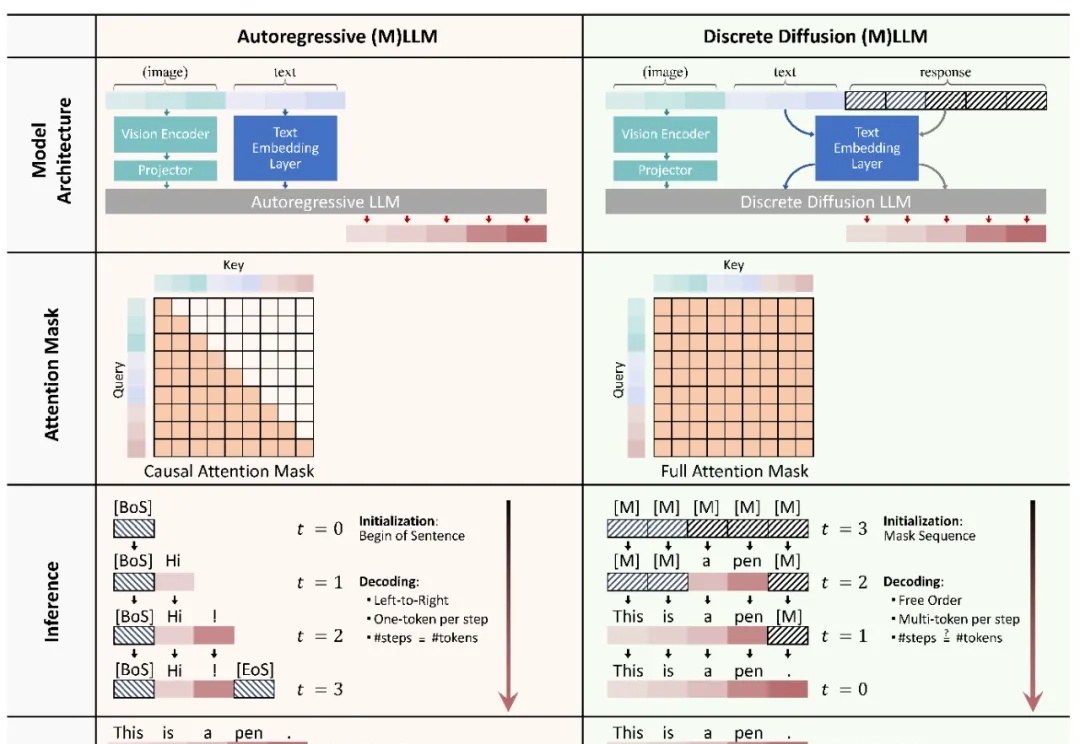
本文主要介绍 xML 团队的论文:Discrete Diffusion in Large Language and Multimodal Models: A Survey。
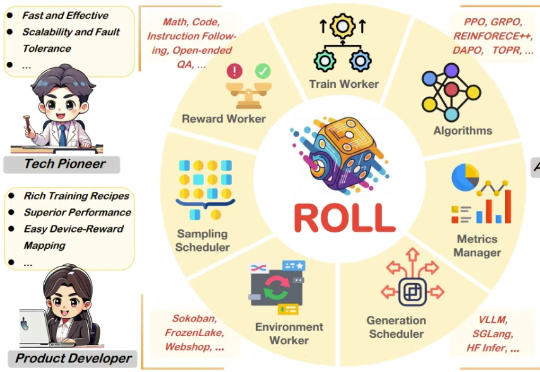
过去几年,随着基于人类偏好的强化学习(Reinforcement Learning from Human Feedback,RLHF)的兴起,强化学习(Reinforcement Learning,RL)已成为大语言模型(Large Language Model,LLM)后训练阶段的关键技术。
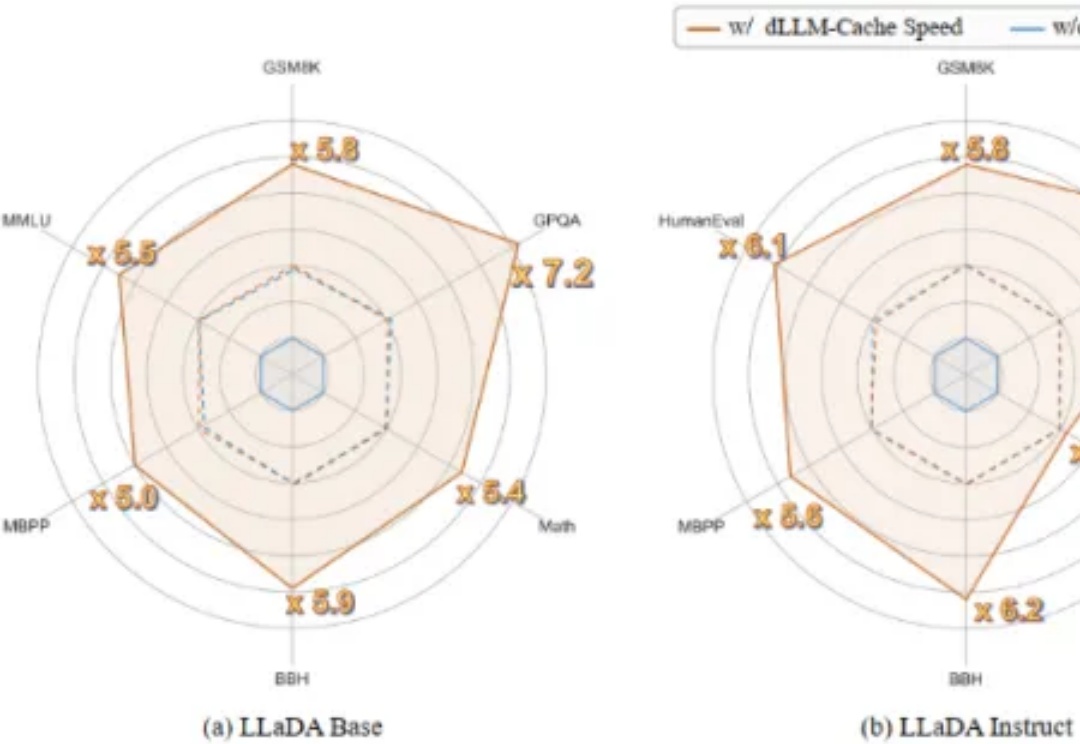
首个用于加速扩散式大语言模型(diffusion-based Large Language Models, 简称 dLLMs)推理过程的免训练方法。
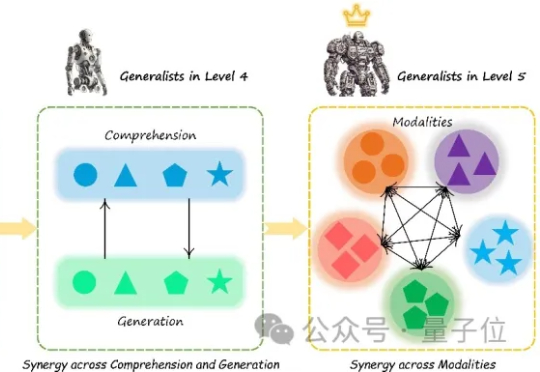
多模态大模型(Multimodal Large Language Models, MLLM)正迅速崛起,从只能理解单一模态,到如今可以同时理解和生成图像、文本、音频甚至视频等多种模态。正因如此,在AI竞赛进入“下半场”之际(由最近的OpenAI研究员姚顺雨所引发的共识观点),设计科学的评估机制俨然成为决定胜负的核心关键。

近年来,大模型(Large Language Models, LLMs)在数学、编程等复杂任务上取得突破,OpenAI-o1、DeepSeek-R1 等推理大模型(Reasoning Large Language Models,RLLMs)表现尤为亮眼。但它们为何如此强大呢?
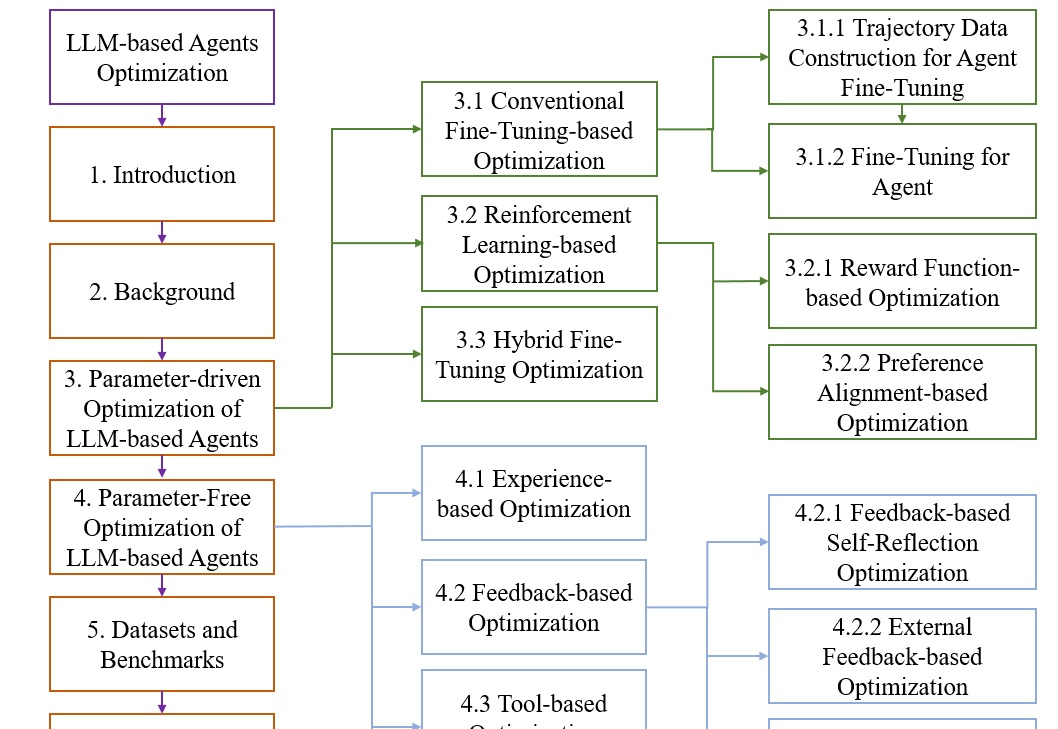
本文基于一项系统性研究《A Survey on the Optimization of Large Language Model-based Agents》,该研究由华东师大和东华大学多位人工智能领域的研究者共同完成。研究团队通过对大量相关文献的分析,构建了一个全面的LLM智能体优化框架,涵盖了从理论基础到实际应用的各个方面。您有兴趣可以找来读一下这篇综述。